Technical delivery · Leadership
Why Most Engineering Teams Fail at Technical Delivery (And How to Fix It)
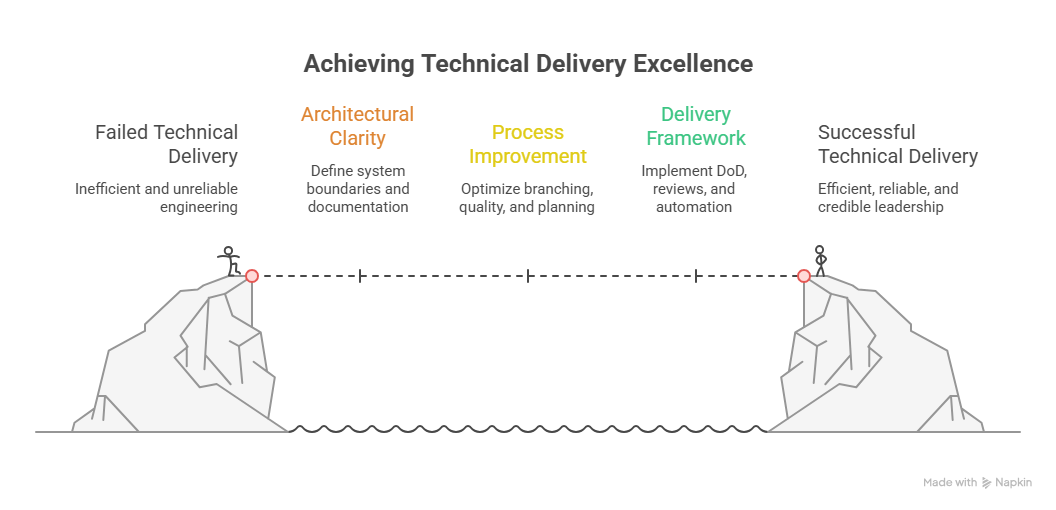
Great engineering isn’t just about smart people or new tools. It’s about clarity of architecture, disciplined process and a delivery framework that teams can trust.
I’ve worked with teams that are full of talented engineers and still struggle to ship reliably. Features slip, quality is inconsistent, and nobody can give a clear answer to “are we ready to release?” The problem is rarely effort; it’s that technical delivery is treated as an afterthought instead of a first‑class concern.
In this article I’ll share how I think about technical delivery as an AI solutions architect and technical delivery leader – from architecture clarity, to process design, to a delivery framework that actually scales.
1. Architecture without clarity
Many delivery problems start before a single line of code is written: the system isn’t clearly defined.
Unclear system boundaries
When boundaries are fuzzy, every feature becomes a negotiation: which service owns this logic, who owns this data, where does this API really belong? Teams end up coupling changes across multiple systems because the architecture never made ownership explicit.
No living documentation
I’m not advocating for 200‑page documents, but I do expect a small set of up‑to‑date diagrams and docs:
- ✓Context diagrams showing key systems and integrations.
- ✓Service or module responsibilities in plain language.
- ✓Deployment topologies for critical components.
2. Process that hurts productivity
Process is supposed to help teams move faster with more confidence. In many organisations, it does the opposite.
Branching and quality gates
A weak branching strategy creates constant friction: long‑lived feature branches, painful merges and surprises late in the cycle. I favour:
- ✓Short‑lived branches with frequent integration into main.
- ✓Automated checks (linting, tests, formatting) as non‑negotiable gates.
- ✓Clear code review expectations: what’s blocking, what’s advisory.
Sprints that mean something
Sprint planning often turns into a wish list. A productive sprint plan is constrained and delivery‑oriented:
- ✓Stories that connect directly to user or system outcomes.
- ✓Capacity that accounts for maintenance, incidents and technical work.
- ✓Explicit alignment on what must ship vs. what is optional.
3. A delivery framework that works
The goal isn’t process for its own sake; it’s a framework that lets teams ship with confidence and iterate safely.
Clear Definition of Done
I like a Definition of Done that is short and ruthless. For most teams it includes at least:
- ✓Tests passing at an agreed coverage and quality level.
- ✓Monitoring and alerts in place for new or changed behaviour.
- ✓Documentation updated where future engineers will look first.
DevOps and automation
Manual deployment and environment management are silent killers of delivery speed. A healthy framework invests in:
- ✓Automated build, test and deployment pipelines.
- ✓Consistent environments (infrastructure as code, configuration as code).
- ✓Safe release strategies (feature flags, canary releases, blue‑green deployments).
Bringing it together
From individual contributors to delivery leaders
Technical delivery is where architecture, engineering and process meet. Treating it deliberately is how teams turn good ideas into reliable systems.
If you make architecture clearer, tune your processes for real productivity and adopt a delivery framework with strong ownership and automation, you give your team room to do their best work. You also make it much easier to iterate on ambitious features like AI systems without losing stability.
If you’d like a second pair of eyes on your own technical delivery setup – from branching to release to post‑incident learning – I’d be happy to help you map it out.